What i know about Spark
Spark là gì?
Spark là một framework mã nguồn mở tính toán cụm. Tốc độ xử lý của của Spark có nhanh do việc tính toán được thực hiện ở bộ nhớ trong (in-memories) thực hiện hoàn toàn trên RAM. (Spark chạy nhanh hơn 10 lần so với MapReduce ở ổ cứng và nhanh hơn 100 lần khi chạy trên RAM)
Spark cho phép xử lý dữ liệu thoe thời gian thực, vừa nhận dữ liệu từ các nguồn khác nhau đồng thời thực hiện ngay việc xử lý trên dữ liệu vừa nhận được (Spark Streaming)
Điểm nổi bật
Xử lý dữ liệu: Spark xử lý dữ liệu theo batch và realtime
Tính tương thích: có thể tích hợp với nhiều nguồn dữ liệu và định dạng tệp được hỗ trợ bởi cụm Hadoop
Hỗ trợ ngôn ngữ lập trình: Java, Scala, Python, R
Phân tích thời gian thực:
- Apache Spark có thể xử lý dữ liệu thời gian thực tức là dữ liệu đến từ các luồng sự kiện thời gian thực với tốc độ hàng triệu sự kiện mỗi giây. Ví dụ: Data Twitter chẳng hạn hoặc luợt chia sẻ, đăng bài trên Facebook. Sức mạnh Spark là khả năng xử lý luồng trực tiếp hiệu quả.
- Apache Spark có thể được sử dụng để xử lý phát hiện gian lận trong khi thực hiện các giao dịch ngân hàng. Đó là bởi vì, tất cả các khoản thanh toán trực tuyến được thực hiện trong thời gian thực và chúng ta cần ngừng giao dịch gian lận trong khi quá trình thanh toán đang diễn ra.
PySpark
Là thư viện trong Python để tương tác, xử dụng Spark.
Create a SparkSession
SparkSession là điểm truy cập vào tất cả các chức năng trong Spark và được yêu cầu nếu muốn sử dụng dataframe trong PySpark.
spark = SparkSession.builder.appName("Datacamp Pyspark Tutorial").config("spark.memory.offHeap.enabled","true").config("spark.memory.offHeap.size","10g").getOrCreate()
Đoạn code trên đã tạo một Spark Session và đặt tên cho application. Sau đó data được cache trong off-heap memory để tránh lưu trữ trực tiếp trên ổ cứng, và dung lượng memory được chỉ định thủ công.
Create the DataFrame
df = spark.read.csv('datacamp_ecommerce.csv',header=True,escape="\"")
param escape được set với " để tránh dấu phẩy trong string.
Để xem 5 hàng đầu của dataframe:
df.show(5,0)
0 nhằm show toàn bộ các cột tránh ẩn bớt thông tin nếu số lượng cột quá nhiều.
Exploratory Data Analysis
Đếm số hàng trong DataFrame:
df.count() # Answer: 2,500
Đếm số khách hàng duy nhất (unique) trong dataframe:
df.select('CustomerID').distinct().count() # Answer: 95
Các giao dịch hầu hết đến từ quốc gia nào:
from pyspark.sql.functions import *
from pyspark.sql.types import *
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).orderBy(desc('country_count')).show()
bảng kết quả trông như sau:

Để tìm thời điểm giao dịch mua hàng gần nhất được thực hiện cần chuyển cột "InvoiceDate" thành định dạng timestamp và sử dụng max() function:
spark.sql("set spark.sql.legacy.timeParserPolicy=LEGACY")
df = df.withColumn('date',to_timestamp("InvoiceDate", 'yy/MM/dd HH:mm'))
df.select(max("date")).show()
Kết quả:
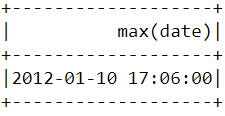
Data Pre-processing
Sử dụng các biến hiện có để rút ra ba đặc điểm thông tin mới - recency, frequency và monetary value (RFM).
- Recency: Mỗi khách hàng đã mua hàng gần đây như thế nào?
- Frequency: Họ có thường xuyên mua thứ gì đó không?
- Monetary value: Trung bình họ chi bao nhiêu tiền khi mua hàng?
Gán recency score cho mỗi khách hàng
df = df.withColumn("from_date", lit("12/1/10 08:26"))
df = df.withColumn('from_date',to_timestamp("from_date", 'yy/MM/dd HH:mm'))
df2=df.withColumn('from_date',to_timestamp(col('from_date'))).withColumn('recency',col("date").cast("long") - col('from_date').cast("long"))
- Dòng đầu tiên tạo một cột mới có tên "from_date" trong PySpark DataFrame "df" và đặt tất cả các giá trị trong cột này thành chuỗi "1/12/10 08:26".
- Dòng thứ hai chuyển đổi cột "from_date" từ một chuỗi sang định dạng dấu thời gian bằng cách sử dụng hàm "to_timestamp".
- Dòng thứ ba tạo một DataFrame mới có tên là "df2" bằng cách áp dụng hai phép biến đổi cho DataFrame gốc "df".
- Phép biến đổi đầu tiên chuyển đổi cột "from_date" sang định dạng dấu thời gian bằng cách sử dụng hàm "to_timestamp" không có đối số.
- Phép biến đổi thứ hai tạo ra một cột mới gọi là "recency" bằng cách trừ Unix timestamp của cột "from_date" với Unix timestamp của cột "date".
- Hàm "col" được dùng để tham chiếu các cột trong DataFrame. Đoạn code này được sử dụng để chuyển đổi cột chuỗi sang định dạng dấu thời gian và tính toán chênh lệch thời gian giữa hai cột trong PySpark DataFrame.
Chọn giao dịch mua gần đây nhất
df2 = df2.join(df2.groupBy('CustomerID').agg(max('recency').alias('recency')),on='recency',how='leftsemi')
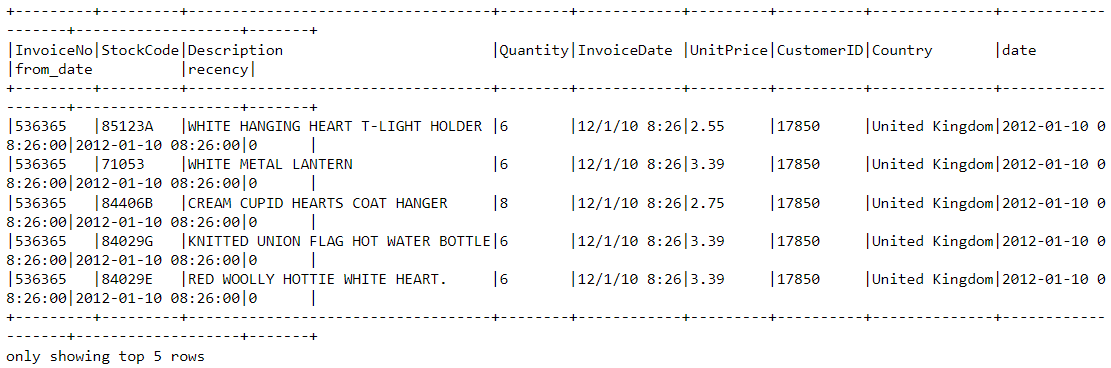
Xem tất cả các biến bằng hàng printSchema. Hàm này tương đường vs hàm info trong Pandas:
df2.printSchema()

Frequency
Chỉ cần nhóm theo từng ID khách hàng và đếm số lượng mặt hàng họ đã mua:
df_freq = df2.groupBy('CustomerID').agg(count('InvoiceDate').alias('frequency'))
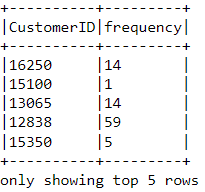
Có một giá trị tần số được thêm vào mỗi khách hàng trong khung dữ liệu. Khung dữ liệu mới này chỉ có hai cột => cần nối nó với cột trước đó:
df3 = df2.join(df_freq,on='CustomerID',how='inner')
Monetary Value
Tìm tổng số tiền chi tiêu trong mỗi lần mua hàng:
Mỗi ID khách hàng đi kèm với các biến được gọi là “Quantity” và “UnitPrice” cho một lần mua hàng:
m_val = df3.withColumn('TotalAmount',col("Quantity") * col("UnitPrice"))
Tìm tổng số tiền chi tiêu của mỗi khách hàng:
Để tìm tổng số tiền chi tiêu của từng khách hàng, chúng ta chỉ cần nhóm theo cột CustomerID và tính tổng số tiền đã chi tiêu:
m_val = m_val.groupBy('CustomerID').agg(sum('TotalAmount').alias('monetary_value'))
Hợp nhất dataframe này với tất cả các biến khác:
finaldf = m_val.join(df3,on='CustomerID',how='inner')
Để chỉ chọn các cột được yêu cầu và loại bỏ các hàng trùng lặp khỏi khung dữ liệu:
finaldf = finaldf.select(['recency','frequency','monetary_value','CustomerID']).distinct()